
Agile and the Theory of Constraints – Part 2: The development cycle
In the last post, I talked about some of the analysis used in lean. Now, let’s see how we can apply the same principles to the software world.
I will start by trying to create a value-stream map. But where to start? There are three levels at which we can do the mapping:
- The entire organization, starting at the idea stage and going through the stage where we ship bits to customers.
- The overall implementation of a feature/MBI/whatever by the development team.
- The inner developer loop for a single story/feature/whatever by a single developer or pair.
I decided to start at #3, spent a lot of time writing, and then realized that the inner loop discussion depends a lot on the other ones, so I put that aside, and decided to start at the outside, with level #1. First issue solved…
I also need to decide what process I am going to map. I’ve worked in a number of different teams with very different processes, many of which I don’t remember perfectly. So, instead of choosing a real team, I’ve decided to invent a composite team that is a bit more on the old-school side of things. Perhaps “old-school interested in building a new school” is a decent description.
The actual process of creating one of the is done through an interactive discussion with a number of people and is very customized to the way a particular organization works. Some of what I create here will not apply to you, so I’ve come up with two ways that might make it more useful for you.
First, I encourage you to draw your own diagram as you read through what I am saying – or perhaps as you read through it a second time. And second, I’ve added a few Question sections where you might want to think a bit about what your answer is before you read mine.
That said, let’s dive in. Our organization builds software, and follows the following steps:
- Enter Idea
- Triage by priority
- Feature estimation
- Release planning
- Create
- Ship
Let’s put those into our first diagram:

Here’s a little bit more information about the steps:
Enter idea
Somebody comes up with an idea, and we need to track it, so it gets entered into a system. This takes about 15 minutes per item.
Traige by priority
Once we have the ideas, we need to order them by priority so we know what the most important ones are. This is typically done by a small group of people who meet for a couple of hours every month.
Feature estimation
To be able to determine which features fit into the release, we need to know how big they are. We will ask the engineering team to do the estimation for us. Since we ask them to give us good estimates, it takes anywhere from 1 to 8 hours of work for them to do each estimate.
Release planning
Before we can start working on a new release, we need to figure out what features we are going to put into it. This is a very important function as it determines what we will invest in for the next release and there are lots of competing priorities, so we set up a release planning group and they spend a lot of time figuring out a draft plan, getting it reviewed, modifying it, rolling it out, etc. It takes about 100 hours for the group to do this, spread over a period of a couple of months.
Create
The engineering team takes the list of features, works through them, and creates the new version of the software. We are using a 2 year ship cycle, so this phase is that two years minus the overhead of planning and shipping, or about 20 months.
Ship
There are things that we need to finish at the end of the cycle; we do acceptance testing and fix the leftover important bugs and go through all the mechanics of putting together the full release. This takes about 2 months.
Let’s add those times to the chart:
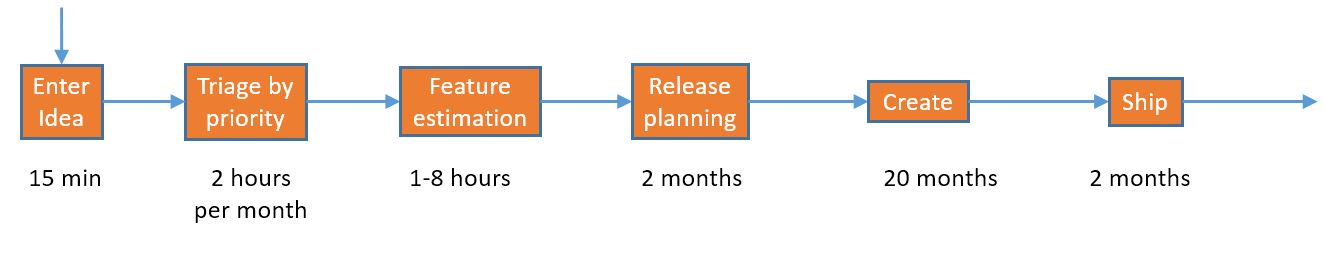
Something you may have noticed is that there are different kinds of times here; “Enter idea” and “Feature estimation” are per-item times, “Triage by priority” is a periodic short meeting, and the rest are just time boxes.
What’s next? Well, those steps just don’t feed directly from one to the next; we have inventory. And wow, we have a lot of it; so much that we give each set of inventory a name so we can tell them apart. We’ll add the inventory with names and counts to the diagram:

These are numbers that I’ve seen for a small product group; one with 20 or so developers on it. They are conservative; I’ve seen examples where the number of prioritized features is well about 500.
There may be a way to express the timeboxed sections properly using the value-stream mapping nomenclature, but I don’t know of one, so I’ll stick to this approach.
Since we will be trying to determine how long it takes a item to move through our system, periodic processing poses a bit of a challenge; one item might get lucky and arrive on the day of the meeting, and another might get unlucky and arrive right after a meeting and have to wait for the next one. We’ll therefore choose an average that is half of the cycle time.
Here’s a little table of our average end-to-end time:
| Step | Inventory count | Elapsed time |
|---|---|---|
| Enter Idea | 0 | 15 minutes |
| Triage by Priority | 200 | 2 weeks |
| Feature Estimation | 200 | 5 weeks |
| Release Planning | 100 | 2 months |
| Create | 50 | 20 months |
| Ship | 50 | 2 months |
| Total | 26 months |
A little over two years for an idea to come in and make it through our system, which is about what we would expect for a 2 year cycle.
Where’s the bottleneck?
Question: In our current system, where do you think the bottleneck lies?
Answer: Our analysis is a little complicated by the fact that many of our operations aren’t full time, so let’s focus on the Create and Ship steps. Let’s express them as rates:
Create: 2.5 features/month
Ship: 25 features/month
So, creation is our bottleneck, which means I’ve spent a lot of words coming to the result everybody was expecting. Let’s continue building the rest of our model to see if we get some more insight into what is going on.
Because of the long lead time – 26 months – this approach cannot be very responsive to changes in business climate or to needs that are discovered as part of the development process. There are different ways to address this; for this part of the discussion, we are going to choose one traditional way of getting there.
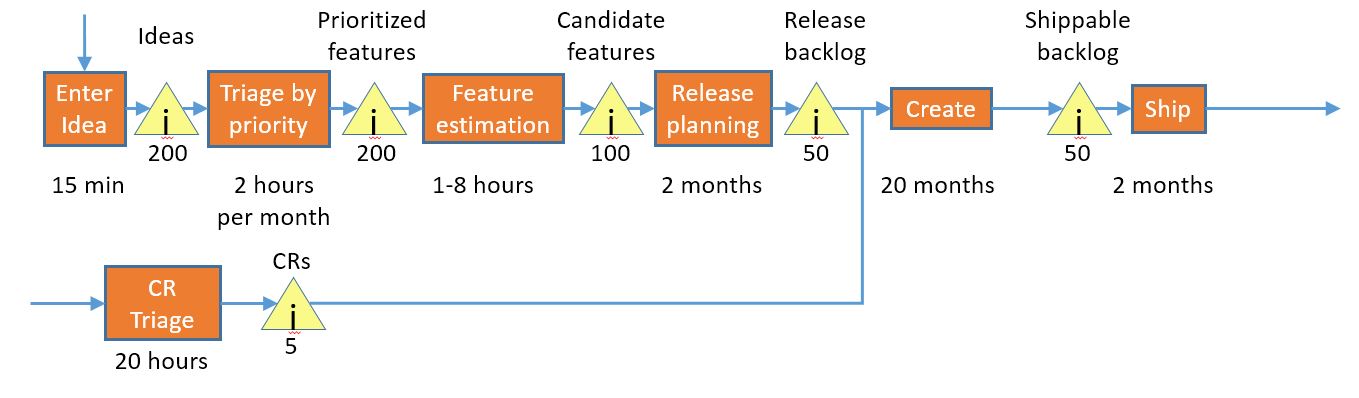
We’ve added a change request process, whereby we identify a small number of very-high-priority features and feed them into the middle of the create process, thereby getting better responsiveness. This feels like an agile and responsive thing to do, but in reality, it really doesn’t help us a ton, for a couple of reasons:
- The later a change request is injected in the cycle, the closer it is to shipping and therefore the shorter the time period is before it will show up as value to our customer, so we want to get the change requests in late.
- The later a change request is injected in the cycle, the more disruptive it is to the development process, and the higher the priority that the ship date will slip, the change request will not be well-implemented, and the overall product will suffer more quality issues, so we want to get them early.
Or, to put it in ToC terms, adding additional destabilizing work to the bottleneck does not yield great results, for obvious reasons.
Pretty much everybody hates change requests, but they are viewed as a necessary evil under this model.
Quality
Our group creates a lot of bugs. Let’s add them into our design:
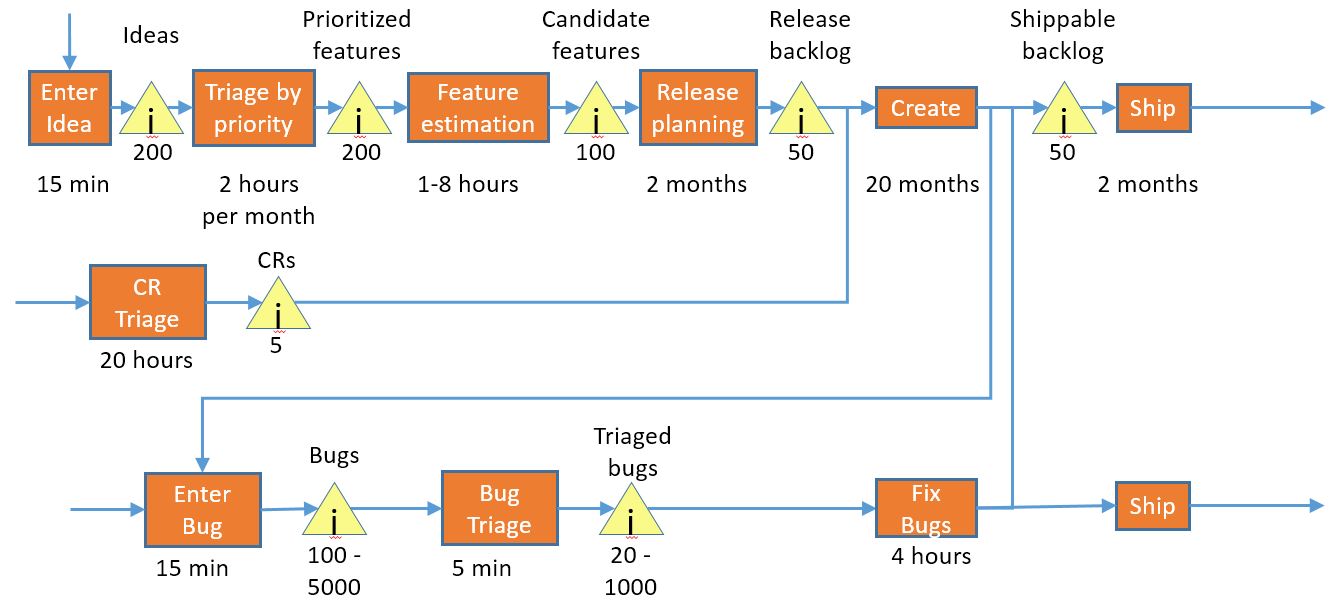
This world of bugs is a complex one. There are weekly triages, bug bars, ship rooms, customer support interactions, service-level agreements, quick fix engineering, hotfixes, service packs, etc. Lots of process.
I spent a while diagramming the process with all of the detail, and quickly realized that if I wanted to include it in this diagram, I had to simplify it considerably, so this is a bare-bones representation. I am not including verification time for bugs, and I’m also not including loop-back for retriaging existing bugs or bugs that were marked as fixed but aren’t, nor am I including regressions. All of which increase the time significantly.
<aside>
If you have a lot of bugs, I highly suggest trying to diagram what happens with bugs including the customer and all the teams that deal with bugs and all the steps you go through. I think it will be enlightening on how much those bugs are costing you.
</aside>
So, anyway, we have two sources of bugs: bugs from the customer that come in from the left and bugs out of the current create step that come in from above. We triage them, and then they are fixed by our development team – the same group that is trying to do the create work. Then we either ship them as fixes to our previous product, or we feed the fixes back into the product under development. Or both.
The time the development team spends fixing bugs is time that they aren’t spending on product work, or – in ToC terms – we have added another stream of work to our bottleneck. How does it affect the total time for an item to go through the system?
Well, if our team fixes 1000 bugs during this long cycle – and that’s not an outlandish number – and they each take 4 hours to fix – also not an outlandish number, then we are spending 500 days of time on bug-fixing. A 20 month project for 10 developers is on the order of 4000 days, so it looks like we are spending around 12% of our time on bugs. Which really doesn’t seem that bad, so we can probably ignore it.
However, if we have a lot of bugs external to the create step, there are also a lot of bugs internal to that step, which are costly. I’ll defer that to the next post.
That completes the creation of our initial diagram. It’s a simplification of the real world, but should server our purposes.
Talkin’ ’bout Optimization
Now that we have identified the constraint, the first thing that we need to do is to exploit it. Which is one of the topics for the next post.
The problem that we have at this level is that we have a significant and very obvious problem – the problem of bugs – but we *have not* attempted to deal with it in the proper way, from within the development team.
Question for the class: Viewed through the lens of ToC, how would you describe the bug triage and fix system? What step does it belong to?
Answer: The whole bug flow is about both subordinating and elevating the constraint.
We have de-optized the process for our non-developers by introducing a new stream of work, which is handled by bug-fix orchestration technicians. They are in charge of looking at bugs, deciding which ones are important enough to fix, deciding when we should fix them, deciding who should fix them, tracking our progress on fixing them, predicting when all of them will be fixed. etc. etc. etc.
And, as this process is obviously costly, we introduce bug-fix orchestration *optimization* technicians, who are responsible for making the process faster. And bug-fix customer advocates, who liaison with the orchestration technicians to make sure that the customer impact of bugs is properly considered. And, in the ship step, we have bug fix coordination meetings, where we get together to make sure we are fixing the right bugs.
And much of this process is handled by our management, which means we are using our high-value assets towards this goal, instead of deploying them towards more strategic concerns.
And I’m still not done…
In my diagram, there’s the section of bugfixing where we are fixing bugs in products that have already been shipped. This takes time away from the developers working on the current product, so we can elevate our constraint by setting up a separate process to handle bugfixing for shipped products.
We create a separate group that is only responsible for bugfixes in our current shipping product, staff it up, and that makes our main process faster. We call this group “sustained engineering”. They are responsible for creating and managing service pack releases to fix the worst of our bugs.
Question: How effective are these approaches at reducing the effect of our constraint?
Answer: Not very. In fact, it can be argued that they make the problem worse.
To draw a manufacturing analogy…
We are building cars, and we have been noticing that when they come out of the paint shop, the doors consistently have some glops of paint on them. We also know that our customers are complaining about the door paint flaking off.
The paint shop is busy creating new doors and also has a lot of doors that need to be redone piled up outside, so we set up a group that looks at all the doors that failed our QC check, takes the ones that we think aren’t bad enough to really bother the customer, and puts them back on the assembly line. Only the very bad doors go back to the paint shop. We look through this whole pile every few months, or at least most of it.
We have customers complaining about gloppy and flaking paint. We tell them that we don’t normally fix those sorts of issues, but if they buy the special extended warranty package, they can get special access to our door fix technicians. We have a separate group who is in charge of doing that – once again, so we don’t slow down the paint shop.
Question: Taking the ToC perspective, what are we missing?
Answer: We missed exploiting the constraint.
It is pretty clear that we have a massive rework problem; we are spending vast amounts of effort fixing issues that are come out of the create process, and it’s so bad that we are ignoring a number of issues that our customers care about. But instead of exploiting the constraint, we are trying to mitigate it from the outside.
I will expand on the bug discussion in a future post, but I think there is an interesting parallel in the manufacturing world.
In the 1950s and 1960s, the US auto industry was quite successful at building products that didn’t have great quality. Then, a bunch of imported cars showed up – cars built by companies that had adopted a very different view on quality, a view that, ironically, came mostly from a number of people from the US.
You probably know how that turned out; the US auto industry learned a painful lesson about trying to compete with companies that are using a better system.
The parallel to software is pretty obvious.
Enough about bugs for now, time to switch topics…
Risk
Risk is something that those of us in development teams really don’t think too much about; that is mostly a topic for the business people. But I’d like to spend a little time on it here.
The two big risks that we need to worry about are:
- Schedule risk – the risk that we will not be able to finish the project on the estimated schedule
- Market risk – the risk that the features that we developed are not longer relevant to our market.
We have a problem with our 2-year cycle; that is quite a long period of time and it is well known that software estimates aren’t very good, so we run a pretty good chance of either being late or having to cut features. Or both. And we have the list of bugs we need to fix, and regressions to fix, and we know that the time to fix bugs isn’t terribly predictable.
There is also a large market risk; we know from our diagram that it takes 26 months for most features to make it through the pipeline, and though we can use change requests to be faster, it will generally only cut our cycle in half, and that’s still fairly long.
This long cycle also requires a fairly large investment of money; a development team of 10 can easily cost $200,000 per month, so over the two years, we’ve put 24 * $200,000, or $4.8 million into the release.
In the theory of constraints, the bottleneck in the system isn’t always something physical; sometimes it’s a policy or choice made by the business. The 24-month cycle is an arbitrary one, and it is something that we could change.
If we pick a shorter approach, we can cut our schedule risk, cut our time to market, and cut our investment. Which seems like a total win to do.
How can we make this change the easiest and safest way? Well, we know how to plan in 2 months, and we know how to ship in 2 months. How about if we shrink the “create” part of the process down to two months, which will give us a 6-month overall cycle (2 months planning, 2 months create, 2 months shipping). Once we do a couple of those and get used to them, we will naturally find ways to cut down the planning part, and we can probably make the shipping part a bit faster as well.
This is a great idea, but it turns out that pretty much nobody does this, and here’s the reason.
In our old system, we were devoting 20 months out of 24 to creating features (well, and bug fixes, but I’m ignoring that for now). If we go to a 6 month cycle, we only get two months worth of “create” in each cycle, for a total of 8 months every two years.
8 months of feature creation is much less than 20, so there is no chance we are going to adopt that approach, despite the fact that it gives us far faster time to market, much less risk, and is something that our team can demonstrably do successfully.
What teams generally do is go for a linear reduction; our 6 month cycle becomes 2 weeks planning, 20 weeks coding, and 2 weeks shipping. Planning works fine – it’s easier, in fact – and development starts the way it always done, and then – as the ship portion approaches – the team realizes the following:
- They aren’t quite done with their features.
- They have a lot of bugs to fix
- All their processes were designed to work in a two-month-long ship step.
- They have absolutely no idea how to ship in two weeks.
Their options are:
- Delay shipping.
- Cut corners
The team generally picks a combination of these. And then, they turn right around and start the next cycle.
There’s another bit of organizational psychology going on here. In a lot of US companies, being bold, aggressive, and making big bets is encouraged and rewarded. That is why we see re-org after re-org; we are doing something significant.
This makes little sense to me. From the agile and lean perspective, we want continuous improvement, because that is the path where the risk is minimized. There is very likely a path that takes the team from a 2-year cycle to a great 6-month, 3-month, or even 1-month cycle, but it’s very clear that you cannot get there just by decree.
That’s all for this post. In the next one, we are going to crack open the create process and see what’s inside.
Recent Comments